这个很简单。熊猫内置了大量的函数和类型,可以快速处理各种日常文件。这里我以txt、excel、csv、json、mysql五种类型的文件为例,简单介绍熊猫如何快速读取这些文件:
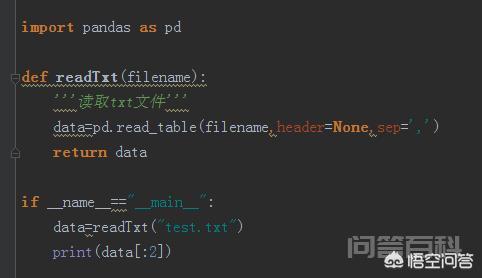
Txt文件这是最常见的文本文件格式。如果读的话,直接用read_table函数就可以了。测试代码如下。在这里,你必须确保txt文件是格式化的,否则读取结果会是错误的。filename是文件名,表头是否包含列头,sep是每一行数据的分隔符,最后读取的数据类型是DataFrame,方便后面的程序处理:
Excel文件这也是一种常见的文件格式。如果读的话,直接用read_excel函数就可以了。测试代码如下,非常简单。直接传入文件名就行了,最后返回的结果也是DataFrame类型:

Csv文件这也是一种常见的文件格式。如果读的话,直接用read_csv函数就可以了。测试代码如下,也很简单。filename是文件名,header是是否包含列头,最后返回的结果也是DataFrame类型:

Json文件也是一种常用的数据存储格式。如果读的话,直接用read_json函数就可以了。测试代码如下。filename是文件名。如果有中文乱码,把编码代码设置成uft-8就行了。最终结果也是数据帧类型:

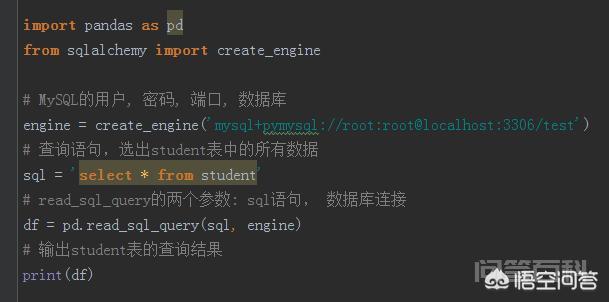
这里mysql需要先安装sqlalchemy框架,然后借助read_sql_query函数就可以直接从mysql数据库中读取数据。如果安装了,直接输入命令“pip install sqlalchemy”即可。测试代码如下,也很简单。首先创建一个connect连接,然后根据sql查询语句直接从数据库中读取数据:
至此,我们已经完成了python的熊猫模块读取txt、excel、csv、json、mysql五种类型文件的数据。总的来说,熊猫是一个强大的模块,尤其是数据处理,可以说是一个利器。它常用于数据分析和处理。只要熟悉相关文档和实例,很快就能掌握。网上也有相关的资料和教程,介绍的很详细。有兴趣的可以搜索一下。希望以上分享的内容能对你有所帮助。也欢迎大家评论和留言补充。